s =
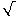 (npq).
(npq).This apology should be made wherever I go near a mathematical symbol but
it is tedious to repeat it on every such page. As I said in a few of my
earliest mathematical pages, my workings have not been independently checked.
I cannot vouch for their correctness. There are bound to be mistakes. We all
make mistakes. But this confession of fallibility needs emphasis here,
because this is the most daring of my innovations. It says that traditional
differentiation is only half the story. When you put calculus on a
statistical basis, there is also the geometric mean derivative.
(Post-script, 9 july 2010: My ideas on statistical differentiation have been
revised on the page: Statistical basis of Differentiation and Geometric Mean
Differentiation of an Interval acceleration.
In the light of that later work, much of the below page seems confused. And,
of course, I realise that the newer page may be only slightly better.)
In the traditional calculus, invented by Newton, and independently by
Leibnitz, differentiation is a means of taking an average at an instant. For
instance, you can take average speeds over ever shorter intervals of time,
until you arrive at the speed at an instant. On a graph, this looks like a
series of chords to a curve approaching the position of a tangent to the
curve. The derivative, or result of the differentiation, is the algebraic
form of the tangent slope.
For example, a parabola is given by an equation such as y = x². Its
derivative works out as 2x, which represents the slope of a straight line.
Differentiations do not have to be worked out repeatedly for every equation.
The above example is a typical case, whose result is known straight away by
rule.
For example, y represents distance and x represents seconds; y = x² might represent the distance, y, say in metres, gone in x seconds. Its derivative (symbolised by Newton as: y' or by Leibnitz as: dy/dx) is: 2x. This equals the speed after x seconds. A table of the speed after each second shows an additional speed of two metres per second. This constant addition of a quantity in each term is the characteristic of an arithmetic series. And the average used to measure it is an arithmetic mean.
Differentiation can be two paradoxical sounding things: instantaneous speed and curvature at a point. No doubt better explanations are readily to hand, and there is a simple example introducing my page: The diffusion equation as a finite difference equation. (That page used the sign: ^ for "a small change in". However Google uses the sign, ^, to show that the following number signifies a power. Thus Google gives x² as x^2. The cubic is x^3 and so on. That is why this page now uses the hash sign, #, for a small change in a variable, a small difference or a differential. To hash is to cut into small pieces, as the sign, #, suggests.)
Differentiation from first principles involves the effect of an increase, say #x, in an independent variable, x, producing an increase, say #y, in a dependent variable, y. The same result is obtained if the increase were replaced by a decrease, in terms of y - #y brought about by x - #x, depending on the precise mathematical form of the relation between the two variables.
Moreover, we could combine the two ways to differentiate from first principles, by differential increase or by decrease, and inevitably still get the same result. This would seem to be a redundant exercise, but when we have done it, it may show differentiation in a new light.
Take the simple example of dependent variable, y, on independent variable, x, in a ratio with the constant, a, so that, for equation 1:
y = a/x.
Differentiate from first principles:
y + #y - y = a/(x + #x) - a/x.
#y = a{x - (x + #x)}/(x(x + #x) = -#x.a/(x(x + #x).
#y/#x = -a/(x(x + #x).
Traditional differentiation is completed by relabeling the ratio of small changes in y and x, as the derivative, dy/dx, when the small change in the independent variable is taken to a limit approaching zero. This eliminates #x from the denominator on the right side of the equation. Hence, equation 2:
limit #x -> 0, #y/#x becomes dy/dx = -a/x².
Exactly the same result is obtained by subtracting the small changes:
y - #y - y = a/(x - #x) - a/x.
-#y = a{x - (x - #x)}/(x(x + #x) = #x.a/(x(x - #x).
#y/#x = -a/(x(x - #x).
This differentiation by decrease repeats the result for differentiation by increase.
Now combine the two versions of differentiation for equation 3:
(#y/#x)² = (-a)²/x²(x + #x)(x - #x).
Taking the square root of both sides, for equation (4):
#y/#x = -a/x{(x + #x)(x - #x)}^1/2.
Again traditional differentiation will still derive dy/dx = -a/x².
But before eliminating +#x and -#x from the right side factors of the equation, notice that part of the denominator, {(x + #x)(x - #x)}^1/2, has the form of a geometric mean. A geometric mean is an average of a geometric series, whereby each successive term increases by a constant multiple.
The two factors (x + #x) and (x - #x) could be taken as the upper and lower bounds of a series. If it was an arithmetic series, then its appropriate average would be the arithmetic mean, which would be equal to x. In an arithmetic series, each successive term increases by an added constant, as for instance the simple series of three terms: (x - #x), x, (x + #x).
The geometric mean is not x but the result of the formula {(x + #x)(x - #x)}^1/2. When the upper and lower bounds are the only terms in the series, their geometric mean is obtained by taking their square root. If there were three terms in the series, all three would be multiplied and their cube root taken for their geometric mean. And so on.
If you were to show the arithmetic series as a graph, it would appear as a sloping straight line. This is also the effect that traditional differentiation produces as the algebraic form to a tangent to the equation of a curve. This suggests a statistical meaning to differentiation.
This page shows that traditional differentiation can be effected by combining the differential increase and decrease options for differentiation from first principles. Then the independent variable looks like a geometric mean form of average before the positive and negative differentials are taken to a limit. The elimination process doesnt completely get rid of the range but makes it so small that it no longer has the form of a geometric series. Its appropriate average is no longer the geometric mean but the arithmetic mean, which averages the kind of constant increase described by a straight line such as a tangent.
There is a half-way house between traditional differentiation and differentiation preserving a geometric mean in the function. That is when the two differentials of increase and decrease are made unequal. From a statistical point of view, traditional differentiation happens to work, by only using an upper bound differential (or only a lower bound), because it could be tacitly assumed that the two bounds are equal.
If you drop that assumption, then the result is other than the traditional one. Say the upper bound is significantly less than the lower bound. Then as you let the upper bound differential approach zero, the lower bound differential may remain a finite value.
One result might be:
dy/dx = -a/x{x(x - #x)}^1/2.
The essence of differing upper and lower differentials is that the larger differential means a wider bound from its variable, which leaves that bound finite when the other bound disappears. In other words, unequal-bounds differentiation leaves a skewed distribution, in statistical terms.
However, it is still possible to study differentiation with geometric means, in terms of the simple situation of equal upper and lower bounds from the variable, which is implicit in traditional differentiation. So that seems to offer the simplest way ahead.
Isaac Newton explained his invention of differentiation in terms of prime ratios and ultimate ratios. This leads to the question whether an ultimate ratio can be found that does not eliminate the geometric mean form, in other words, a non-linear differential calculus of geometric mean functions.
From equation 3:
(#y/#x)² = (-a)²/x²(x² - #x²) = (-a)²/x^4(1 - #x²/x²).
From equation 4:
(#y/#x) = -a/x(x² - #x²)^1/2 = -a/x²(1 - #x²/x²)^1/2.
The trick of geometric mean derivation would seem to be to raise this equation to the power of the inverse of the independent variable's differential squared, 1/#x². Why the inverse? Because differentiation involves letting the differential approach zero, but we dont want a power approaching zero but approaching its inverse, which is infinity. From the right side of equation 4, this powered factor, (1 - #x²/x²)^1/2#x², can be transformed to an exponential function. This factor has been put in the form of the binomial theorem. Raised to an infinite power, this transforms a binomial series into an exponential series.
Hence equation 5:
(#y/#x)^1/#x² = (-a/x²)^1/#x².{1/(1 - #x²/x²)^1/2#x²}.
Now performing the traditional principle of taking #x to a limit approaching zero. (For geometric mean differentiation, this also implies the power, 1/#x² approaches infinity.) This finalising of differentiation is signified by changing #x to dx, and #y to dy.
Here we might say: As #x² -> 0, 1/#x² -> ∞, for equation 6:
(dy/dx)^1/dx² = (-a/x²}^1/dx²).{1/e^-1/2dx²}.
Or:
(dy/dx)^-1/dx² = (-a/x²}^-1/dx²).e^-1/2dx².
The letter, e, is for the exponent.
Another invention of Isaac Newton was the binomial theorem. Taking a certain variable, in the theorem, as a power approaching infinity, can change a binomial series into an exponential series, which is a function of a special number called the exponent, "e" or "exp" for short. This number has the value 2.718... continuing indefinitely. The exponential series computes its value for an infinite number of terms in logical progression from one term to the next in the series.
It so happens that the binomial theorem can be adapted to a geometric mean
form, which is how equation 5 transforms to equation 6.
See appendix 1 for a fuller explanation found in standard text books.
The worm in the bud of this flowering result, for a geometric mean derivative, is that the coefficient, (-a/x²)^1/dx², is infinite unless it can be made into unity. The simplest option is to make: -a = x². Or, make a = x², and the exponent term would be: ±{1/e^-1/2x²}.
This in turn means that the original function, y = a/x, has the identity, y = -x, or perhaps y = x, for it to have a well-defined geometric mean derivative. In graphical terms, y = x is given by a straight line thru the origin of the x-y co-ordinates, at forty-five degrees to both axes. In other words, it is the simplest linear function.
Even an equation like E = mc² is not a perfect identity. It is actually a good approximation using the first two terms of a binomial series. On the other hand, it is possible that an extremely restrictive procedure for a well-defined geometric mean derivative might be used as a test for whether an equation is a true identity or just a very good approximation.
At any rate, some exponential function can be considered in the new light
of a geometric mean derivative, which can be traced back to its
anti-derivative. This is attempted, below, for the equation of the normal
distribution.
This example shows that the procedure need not be so restricted. The
independent variable's differential can be changed so that constant, a,
compensates for the change.
But first, what does a geometric mean function entail? It means that we are defining any given function as having a certain kind of statistical distribution or graphical shape. To put it in simple terms. Suppose you have a sum of money you want to invest. You might be offered 20% interest per year, on terms of simple interest. That means every year you get twenty more currency units for every hundred you have saved.
Or you might be offered 10% interest per year, on terms of compound interest. That means that the ten units may be added to the hundred after the first year, so that the interest is on 110 units next year. Compound interest is a geometric mean rate of interest, an average rate of interest on an accumulating capital. Before long you are earning more from compound interest on the lower rate than on simple interest at the higher rate.
The shape on a graph of simple interest is of an upwards sloping straight line increasing at intervals by 20 units at a time. The average interest earned is a constant 20 units per year. That is an arithmetic mean interest.
For compound interest, the calculation has to be done by geometric mean. The successive compound interests form a geometric series, which graph as an increasingly steep curve upwards (an "exponential" curve).
Compare the two curves for simple and compound interest. For a while simple interest's upward sloping straight line will offer higher returns, if offering a higher interest, and be above the compound interest curve, till its gradually increasing steepness passes above the straight line and shoots upward.
Say that you have a "function" called "five per cent interest". It still remains to define that function as an "arithmetic mean function" or "linear" function. But one could also define a given function as a "geometric mean function" or exponentially curved function.
Before treating the equation of the normal curve, in terms of a geometric mean derivative, there follows some explanation of this curve as a probability distribution.
The normal curve was published by De Moivre in 1733, and independently discovered by Gauss and Laplace. This is the exponential version of the binomial distribution. In graphical terms, the normal curve is the famous bell-shaped curve, a smoothed-out version of the binomial distribution.
If you take the numbers in the rows of Pascal's triangle and graph them, the further down the triangle you go, the more detailed the distribution, the less crude the graph, the closer to the normal curve. (That is as long as the scale or magnification is not increased to show the increased detail of bigger distributions.)
A simple form of the equation for the normal curve is equation 7:
w = exp^-z²/2.
It's like the exponential form in equation 6. Here "e" or "exp" is short
for the exponent, an infinite number starting 2.718... The sign,^, is to show
that the exponent is raised to the power, -z²/2.
This is not quite the standard form of the equation, which includes a
constant coefficient (the inverse of the square root of twice pi) whose
purpose is merely to standardise to unity the area under the curve. This is
multiplied by another standardising coefficient, 1/s, the inverse of the
standard deviation, which slightly complicates the working.
The standard form of the normal distribution is thus:
w = {1/(√2π)s}exp^-z²/2.
The value, w, is the height at any graph point along the bell-shaped curve. For example it could measure the number of people by height in ordered steps. It is not a measure of their heights, as such, but a measure of how many people are of a given height when ordered in a line from shortest to tallest.
Most people come more or less in a compact range in the middle of the bell-shape. There are a relatively few very tall and very short people, whose numbers fall off very rapidly. These are the big drop in numbers represented by the wings of the bell compared to the high frequencies of middling heights represented by the bell's dome.
The coefficient wont enter into our working, so we'll refer to the simpler equation 7. The variable, z, is also a standardising term, so that all normal curves may be compared. z = (m - np)/s. This term is most simply explained in terms of the normal curve's approximation, the binomial distribution. See table 1.
| probable times an event occurs: | 1 | 4 | 6 | 4 | 1 |
| number of events, m: | 0 | 1 | 2 | 3 | 4 |
| number of events, m, standardised for A.M.= 0: | -2 | -1 | 0 | 1 | 2 |
The table may show, for example, the relative probability that an event
will happen, zero, or one, or two, or three or four times. Suppose we have a
bag of sweets, with an equal number of black to white. Suppose we randomly
pick out samples of four sweets: n = 4. Then we would expect, in terms of the
binomial distribution as an approximation, that in one case, none of the
sweets is black; in four cases, one of the four sweets is black; in six
cases, two of the sweets are black; in four cases, three of the sweets are
black; and in one case, four of the sweets are black.
The same argument follows for white instead of black, as they are in equal
numbers. The variable, n, does not have to equal four. For instance, it could
equal eight, in which case the black and white frequencies of the random
possibilities would follow the binomial distribution, or Pascal's triangle,
for n = 8.
There is a text-book probability formula for generating these discrete
numbers, which graph in steps. (I used it on my page: The diffusion equation
as a finite difference equation.) The normal curve equation smoothes such
steps into a continuous curve.
The larger number of items in a sample, the more gradual the changes between
them for any given measure, until the change seems virtually continuous.
Thus, the normal curve implies large numbers in its distribution or range.
From the example in table 1, the average probability is that the event happens two times. Formally, this average, the arithmetic mean, A.M., can be calculated most simply here by A.M. = np. Here p means a probability of one half. That is: np = 4.1/2 = 2. For example, from all the random samples of four sweets each, on average, two of the sweets are black (or by the same reasoning, two are white).
The remaining probability is assigned the letter q. In this case q is one half, because total probability is unity. If p is probability of success, q is probability of failure. If you were only allowed to pick out randomly four sweets at a time, but wanted black liquorice sweets, then your probability of success with picking the black sweets would equal your probability of failure from picking the white sweets.
Unequal probabilities, or probabilities other than one half, say one-third probability of success, p, apply, say, if only one-third of three kinds of sweets are desired. This leaves two-thirds probability of failure, q. The greater the inequality of probabilities, the more skewed the binomial distribution.
The letter, s, in the normal curve formula, stands for the standard
deviation. (Texts use the Greek letter sigma, σ.) Whereas an average
represents the most typical item in a distribution, the standard deviation is
a measure of the dispersion or spread of a distribution. Its formula is the
square root of the multiple npq, or:
s = (npq).
In the above example, s = 4.(1/2)(1/2) = 1. Two standard deviations, either way about an average, are reckoned to cover about 95% of the area under a normal curve or its stepped version, the binomial distribution. Our simplistic example is an unrealisticly small sample for statistical purposes. And in its case, two standard deviations covers the whole spread of the distribution, which is only plus two or minus two about the average. (See row three of table 1.)
Going back to: z = (m - np)/2s, in its standardised form, np is re-set to zero, and m becomes, in the above example any of the values: -2, -1, 0, 1, 2. The minus signs dont affect the result because z is squared in the normal curve formula. This exponential formula yields counter-part values to the terms of the binomial distribution. The results dont coincide very closely for small distributions like this one. (And you have to adjust with the above-mentioned area coefficient in terms of the inverse of the square root of twice pi.)
For this page's new take on traditional differentiation, transformed into a geometric mean differentiation, the recipe might be as follows.
Take any function and transform it into a geometric mean function. Bound the function's variables (say x and y) with both upper and lower differentials. Follow traditional differentiation from first principles on both pairs of boundary differentials. Multiply the results and take their square root. This gives their geometric mean. But do not yet eliminate any differentials by taking them towards a limit of zero.
Next, treat the geometric mean in terms of the binomial theorem. Then, essentially, perform a geometric mean differentiation by raising that geometric mean in the form of the binomial theorem, to the power of the independent variable's differential inverted. The power differential, taken to a limit of zero, when inverted, is, in effect, a power taken to infinity. Geometric mean differentiation works by making use of the well-known trick of transforming a binomial series into an exponential series.
This explains the principle of the new take on traditional differentiation. But of course you cannot expect that to mean much until this page gets further on with its meaning in practise.
I worked out the practical details backwards (a time-honored trick of mathematicians, as well as myself) from the result I want, to arrive at first principles.
This section will work with a simplified version of the normal curve, by making m = qn. (The next section will work with the more complicated standard version of the normal curve. The difference in results doesnt amount to much.)
The effect on a graph, of simplifying the normal curve, in this way, is to turn a bell-shaped curve into a tent-shaped curve. The "tent" shape is actually two exponential curves, back to back on the graph paper. This is a much less interesting curve than the normal curve but it simplifies the following working in this section.
The variable, m/n, has been replaced by q because q is related to p: p + q = 1. The probability of success plus the probability of failure equals a whole probability or certainty.
There is a well-known text-book way of converting the binomial theorem and series into an exponential series, bearing in mind that the binomial theorem can be cast as a geometric mean.
Given the simplification, m=qn, then: y = exp^-z²/2 = exp^-(nq-np)²/2s².
A binomial theorem form is: ( 1 - z²/2n)^n.
As n -> infinity, this form derives equation 7 again: w = exp^-z²/2.
Texts show this relation by expanding the binomial theorem form into its binomial series. The infinite-valued n terms cancel or reduce fractions to zero, when denominators, resulting in an exponential series, which sums in terms of the exponent. (See appendix 1.)
Notice, in the binomial theorem form, the variable, n, is not only a power but also appears inside the brackets, where it was not before.
Working backward to our goal of geometric mean differentiation from first
principles, we can dismiss the power n (that is: ^n) until we are ready for
it again, and concentrate on ( 1 - z²/2n). This term can be considered as the
square of a geometric mean. We can factorise it as: (1 - z/{2n})(1 + z/{2n}).
This factorisation can be considered statisticly as a distribution about
the unity value by plus or minus z/{2n}. If this distribution formed an arithmetic series of terms, then unity
would be the arithmetic mean. But as a geometric series, you obtain the
geometric mean by multiplying the differences plus and minus unity, which
respectively are the values of two terms (the distribution's upper and lower
bounds) then taking their square root.
We have a geometric mean, but we still have to work back to a new form of differentiation, geometric mean differentiation, from first principles. The exponent to a negative power is simply the inverse of the exponent to a positive power. Deriving the positive form from the binomial theorem would simply involve changing the sign to positive in the brackets, in equation 8:
(1 + z²/2n) = {1 + (nq - np)²}/2ns² =
{2ns² + (nq - np)²}/2ns².
But:
2ns² + (nq - np)² = (nq)² + (np)² = (nr)².
The form: p² + q² = r² is Pythagoras' theorem.
To make the symbolism less clumsy, let nr = R, nq = Q; let np = P.
Re-stating equation 8, so:
R²/2ns² = {2ns² + (nq - np)²}/2ns².
= (2ns² + s²z²)/2ns² =
Therefore, equation 9:
R² = (2ns² + s²z²) = s²z²2n(1/z² + 1/2n).
To get a geometric mean form in equation 9, rather like equation 3, invert both sides of the equation. Multiply the right side by (1/z²)/(1/z²). And take (1/2n) to the left side. Thus, equation 10:
1/R²/(1/2n) = (1/z²)(1/s²z²)/(1/z²)(1/z² + 1/2n).
The constant a² = 1/s²z^4. That is the right side numerator. And -a = sz².
Relating the variables, in my geometric mean version of differentiation
from first principles, to this example, let x² = 1/z² and #x² = -1/2n. x =
1/z but #x will be i(1/2n^1/2).
The imaginary number in the differential, is from thinking in terms of (1/z²
+ 1/2n) = (1/z² - i²/2n). This is because this factor is considered as the
square of a geometric mean. This must transform into two factors, one an
addition, the other a subtraction. These factors are the upper and lower
bounds of a range, essentially a geometric series, of which the geometric
mean takes a representative value or average: Most simply, the range
end-values are multiplied together and their square root taken.
Hence: ( 1/z² - i²/2n ) = (1/z + i/{2n^1/2})({1/z - i/{2n^1/2}.
Let -1/R² = (#y)² = #y². (It's just a simplifying convention to remove the brackets for the squaring of a differential.)
#y = i/R is the differential of a new variable, y. Later, we can work out what y might be. (Because #x is imaginary, it turns out to be convenient to make #y imaginary as well.)
Re-write equation 10 in terms of the ratio of the two variables' differentials squared, for equation 11:
#y²/#x² = (-1/R²)/(-2/n) = a²/x²( x² - #x² ).
Equation 11 is the same as equation 3, having transformed the normal distribution equation into the process of geometric mean differentiation from first principles. The right side of equation 11 is also assumed to involve the square of two negative values, because these arise whether differentiating with positive differentials or negative differentials. (This is shown in equations 3 and 4.)
Compare equation 4 in taking the square root of equation 10 for equation 12:
i/R/{i/(2n)^1/2} = (1/s)/(1 + z²/2n )^1/2}.
Substituting in equation 5 the normal curve variables, where 1/#x² = -2n. Assume s=1. Hence, equation 13:
{i{1/R)/i({1/2n}^-2n = {(1 - -z²/2n )-2n/2}.
Taking #x² = -1/2n to a limit of zero, and therefore 1/#x² = -2n to infinity, leads to the geometric mean derivative. With reference to equation 6, this leads to equation 14:
(dy/dx)^1/dx² = {e^-z²/2}.
(Equation 14, unlike 6, is not the inverse of the normal curve. But we worked back from equation 7 of the normal curve, not its inverse.) The standard form of the equation of the normal curve, e^-z²/2, comes with a constant coefficient, 1/s√2π. In the standard form, the standard deviation, s, is equated to one.
The geometric mean anti-derivative for the "tent" curve:
It's worth going over again this example of the normal curve (restricted by m = qn, from a bell curve to a "tent" curve) in terms of the new statistical version of differentiation from first principles. Infering the original function of the geometric mean derivative is akin to finding the anti-derivative (or integral) in traditional calculus. It may seem a surprise at first but the correctness of the infered original function can be tested by deriving the working leading up to equation 14.
The condition for the well-defined geometric mean derivative was: -a = 1/sz² = x²/s.
We infer the original function or anti-derivative, from equation 1, to be equation 15:
y = a/x = (-x²/s)/x = -x/s = -1/sz = -1/n(q-p) = -1/(Q-P).
(Remember the restriction for the "tent" curve, m = nq.)
Traditional differentiation of equation 15 is given by rule as equation 16:
dy/dx = -a/x² = 1/s.
This section drops the m=qn restriction to return to the proper normal distribution. It also works from the negative powered exponent, instead of the positive powered exponent.
(17) Given that: w = exp^-z²/2 = exp^-(m-np)²/2s².
Then the binomial theorem will derive this from (18):
( 1 - z²/2n)^n.
As n -> infinity, y = exp^-z²/2.
Working backward to our goal of geometric mean differentiation from first
principles, we can dismiss the power n (that is: ^n) until we are ready for
it again, and concentrate on ( 1 - z²/2n). This term can be considered as the
square of a geometric mean, when we factorise it as the two bounds, of a
geometric series, multiplied together: (1 - z/{2n})(1 + z/{2n}).
Hence, equation (19):
1 - z²/2n = 1 - (m - np)²/2ns² = {2ns² - (m - np)²}/2ns²}.
Notice that equation (19) does not impose the previous section's restriction that m = qn. This is because 1 - z²/2n (unlike its positive version,1 + z²/2n, in the section above) does not tempt a simplistic assumption of Pythagoras' theorem. It is still possible to use Pythagoras' theorem provided we use a complex variable to find R².
Hence equation (20):
(1 - z²/2n)2ns² = 2n²pq - {m² + (np)² - 2xnp}.
Re-group equation (20) for (21):
(1 - z²/2n)2ns² = {(2pn(m - qn) - {m² + (np)²}} = R².
Applying Pythagoras' theorem finds a complex variable, (22):
{(2pn)(m - qn)}^1/2 + i({m² + (np)²})^1/2 =
{2n(pm - s²)}^1/2 + i{m² + (np)²}^1/2}.
Suppose this complex variable's real and imaginary parts are right-angled co-ordinates dividing a circle. Then the sum of their squares equal the square of the radius, R².
To get a form, resembling geometric mean differentiation, invert equation (21), and use the unitary multiple, (1/z²)^2/{(1/z²)^2} on the right side:
1/R² = (1/2n)(1/z²)^2/{(1/z²)^2}(1 - z²/2n)s².
Therefore (23):
1/R²/(1/2n) = (1/s²)(1/z²)^2/{(1/z²)(1/z² - 1/2n)
Let 1/R² = (#y)² = #y². (It's just a simplifying convention to remove the
brackets for the squaring of a differential.) Then #y = 1/R is the
differential of a new variable, y. Later, we can work out what y might be.
Also let #x² = 1/2n and #x = (1/2n)^1/2.
Let a² = (1/s²)(1/z²)^2 = x^4/s². Then -a = 1/sz² = x²/s. The constant, a, is negative, from the square of two negative values, of constant, a, that arise, in differentiation from first principles, whether differentiating with positive differentials or negative differentials, both being performed during geometric mean differentiation. (See equation 3.)
This gives a form fit for geometric mean differentiation, (24):
#y²/#x² = a²/x²( x² - #x² ) = a²/x^4(1 - #x²/x²) = 1/s²(1 - z²/2n)
Taking the square root for (25):
#y/#x = -a/x²(1 - #x²/x²)^1/2 = 1/s(1 - z²/2n)^1/2
To make equation (25) a geometric mean derivative, raise both sides to the power of the inverse differential squared, 1/#x², of the independent variable, x. Then let the differential squared approach a limit of zero. The inverse differential squared approaches infinity. Thus equation (26):
(#y/#x)^1/#x² = {-a/x²(1 - #x²/x²)^1/2}^1/#x² =
{1/s(1 - z²/2n)^1/2}^2n =
{(1/s)^2n}{1 - z²/2n}^n.
As #x -> 0, the ratio (#y/#x)^1/#x² is given the new notation, (dy/dx)^1/dx². This symbolises geometric mean differentiation. (Traditional differentiation simply has the notation, dy/dx.) The standard deviation, s, is given its standardised value of unity. Hence equation (27):
(dy/dx)^1/dx² = e-^z²/2.
One may wonder why the power, 1/dx², has to be a square which does not correspond to the differential, dx, as part of (dy/dx). But the squaring of dx, in the power, simply relates to the necessary procedure for taking a geometric mean, when the upper bound is multiplied by the lower bound.
As mentioned above, this page has only taken the simple case where the upper and lower bounds, of a variable's range, are the same distance, #x, from unity. Thus taking the geometric mean involves squaring #x: signified (#x)² or more conveniently, #x². To show that the limit has been taken, as #x² approaches zero, this symbolism is converted to dx². The power is 1/dx² to make the power approach the inverse of zero, which is infinity.
Had we used unequal upper and lower bounds, say, #x,1 and #x,2, in their distance from unity, then their multiple would be: #x,1#x,2, which might be reduced for convenience to simply: #x,2 to show two unequal bounds multiplied.
The geometric mean extends to dealing with more than just the two outer bounds of a series, it can also take the measure of a whole geometric series of terms. If the series is exactly known, with every term graphing exactly on some curve, then the two end terms are sufficient to calculate the geometric mean exactly. You can include more terms and still get the same result.
Not knowing the exact nature of the series but just having a series of observed points that appear to fit some sort of geometric series, then it is an advantage to calculate as many points as possible, because that is more likely to reduce any observational errors, and reach a value closer to some geometric mean, if that is the true function.
Suppose you had six points above unity and six corresponding points below unity, then the notation for multiplying these might be: #x,12 or say: #x²,6 changing to dx,12 or dx²,6 after completing geometric mean diferentiation. I dont particularly recommend this symbolism (even if my key-board limitations were removed). I'm just trying to remove any sense that the left side of equation (27), (dy/dx)^1/dx², somehow doesnt look right, because one dx is squared when the other dx is not squared.
Should the above procedure not be rigorous enough, it is still possible to have a geometric mean derivative in terms of (dy/dx)^2/dx² = e-^z². And this result could be modified by changes in the values given to the variables and their differentials.
There is a mirage-like resemblance of the generalised geometric mean to traditional differentiation when repeated. Every extra term in a geometric series must be multiplied and then the root taken to the power of the number of terms. Two terms are multiplied and have their square root taken. Three terms are multiplied and have their cubic root taken, etc.
Whereas with traditional differentiation, a second order derivative typicly involves (not always, of course) a square of the independent variable, a third order derivative typicly a cubic, and so on. If you wanted to find the value of the independent variable you might take the relevant root of its expression in a derivative.
Another mirage-like resemblance between geometric mean differentiation and traditional differentiation is in the role they both have for an arbitrary constant. The reverse process, of traditional differentiation, is generally completed by adding a constant. This is because differentiation eliminates a constant and so if you anti-differentiate, there is always the possibility that there was an extra constant in the first place. The arbitrary nature of the constant can make the function, in question, take on a cascade of values.
With geometric mean differentiation in reverse, it is also necessary to assume an arbitrary constant, tho in a different way and for a different reason. This is not an added constant but a multiplied constant, to reduce a coefficient to unity, so that taking it to infinity cannot render the geometric mean derivative indeterminate.
As a consequence, this arbitrary constant must appear in an original funtion or anti-derivative, implied in an exponential function considered in terms of a geometric mean derivative.
The original function or anti-derivative (or "integral") of geometric mean derivative equation (27) is, from equation 1, equation (28):
y = a/x = (-x²/s)/x = -x/s = -1/zs = -1/(m-np).
The traditional derivative is known by rule to be equation (29):
y = -a/x² = -(-x²/s)/x² = 1/s.
Applying differentiation or reverse differentiation, using the traditional calculus on an exponential equation, like equation (27), would only re-produce the exponent multiplied by some different constant. (The difference would be invisible if the constant was unity.)
Whereas geometric mean differentiation generally produces an exponent and its reverse removes the exponent, reducing the independent variable from the infinite to the finite. (That is, provided its coefficient could be set reasonably at unity, which would be unaffected by its being raised to an infinite power during the process of geometric mean differentiation.)
This adaptation of the calculus offers a method of solving geometric mean functions, which are a different type of function to the type assumed in the process of traditional differentiation.
Notice that with traditional differentiation, the independent variable, x = 1/z, was eliminated, and the standard deviation term, s, retained. But with this new kind of power derivative, s has to be reduced to unity, to get rid of the infinite power, and z²/2 has become the power of the exponent, e.
Can we say a bit more about the geometric mean derivative, equation (27)? Remember that #y was the inverse of radius R and that #x was (1/2n)^1/2. Moreover, it was possible to consider both variables with imaginary signs, (which was done, in the earlier restricted treatment of the normal curve as a "tent" curve: equation 12).
On my page about Mach's principle applied to math, it was shown that iR could be interpreted as a geometric mean radius. The imaginary number is an operator which signs the radius to turn thru a quadrant of a circle. The quadrants are represented by certain complex numbers or their conjugates, which are in effect the bounds of a range of which the radial geometric mean is the "average."
But radius, R, or 1/#y, is still in terms of a differential to some original variable radius, y, identified in equation 28. Transforming that equation, (m-np) = -1/y, may be considered as an original radius. Using Pythagoras' theorem, its co-ordinate axes may be found from equation (30):
(m-np)² = m² + (np)² - 2mnp.
Equation 30 may represent a circular function with real and imaginary axes. The so-called imaginary axis merely represents a second dimension at ninety degrees to the so-called real axis. The term, imaginary, is just a historical name: its distinct axis is just as "real" as the real axis.
The real axis squared is equation (31): m² + (np)² = F².
In the degenerate case of the normal curve, the "tent" curve, where m = qn, then: (qn)² + (np)² = R². (See working between equations 8 and 9.) The unrestricted version, where m is not equal to qn, is equation (20). And radius R for the unrestricted normal curve is equation (21).)
Hence, in equation (31), the real axis has to be given a distinct symbol, F. The imaginary axis is the square root of -2mnp. That is: i(2mnp)^1/2.
Thus, the geometric mean differentiation of equation (28) considered as a circular function results in the normal curve, as its derivative, equation (27). Conversely, taking the equation of the normal distribution as a geometric mean derivative (equation (27)), anti-differentiation reveals a circular function to its anti-derivative, in equation (28).
In the restricted case, of the "tent" curve where m=nq, the circular function with its complex number co-ordinates (infered from equation (28)) is reduced to just real numbers for both axes, P and Q, of a circle of radius, R (infered from equation 15).
So far, geometric mean differentiation works like traditional differentiation from first principles and by taking the independent variable differential to a zero limit, with an extra twist of powering its inverse. It also has its own kind of rule-governed anti-derivative.
Can we go a step further and say that geometric mean differentiation may be repeated on a function so that we can speak of orders of differentiation, as occurs in traditional differentiation? The answer could be a qualified yes.
Using the values: x = 1/z and a² = x^4/s² and -a = x²/s = 1/z², if s=1. Also #x = (√1/2n) and #y = 1/R.
And given {from equation (28)} that:
y = a/x = (-x²/s)/x = -x/s = -1/zs = -1/(m-np).
If s = 1, y = -x, the anti-derivative of a geometric mean derivative is an identity, the simplest of linear relations. (The sign could be changed under slightly different assumptions and doesnt alter the essential relation.)
Assume equation (28) is the geometric mean anti-derivative of a second order derivative, in equation (27), then we have to find, if possible, the first order derivative and its anti-derivative.
Then re-arrange (28) for equation (32):
y = -1/(m-np) = -(1/n)/(p - m/n).
Using a unitary multiple, (p/2m)/(p/2m), this is put in a geometric mean form, such as could be derived from first principles, in equation (33):
y = -(1/2nm)(p/2m)/(p/2m)(p/2m - 1/2n).
In the numerator, possible value for constant, a² = p/2m².
The denominator's geometric mean form has to be converted into binomial theorem form before it can be transformed into an exponential form. Hence equation (34):
y = -(1/2n)(p/2m²)/(p/2m)²(1 - 2m/2np).
Therefore (35):
(-yp/2)/(1/2n) = 1/(1 - 2m/2np)
Let #u² = -yp/2 = -p{-1/(m-np)2} = p/2(m-np).
Remember #x² = 1/2n.
Taking the square root of both sides of (35) for:
#u/#x = 1/(1 - 2m/2np)^1/2.
And raise both sides of equation (35) to the power of 1/#x² = 2n Then (36):
(#u/#x)^1/#x² = {1/(1 - 2m/2np)^2n/2.
As #x² -> 0, 1/#x² -> infinity, then equation (37):
(du/dx)^1/dx² = 1/(e^-{m/p}) = e^(m/p).
Alternatively,
(du/dx)^-1/dx² = (dx/du)^1/dx² = e^-{m/p}.
Can we describe this as a first order geometric mean (GM) derivative, designating equation (27) as a second order geometric mean derivative? They both have the same independent variable differential, #x, which is perhaps a minimum requirement, to bear comparison with traditional differentiation.
Further-more, a first order GM derivative should have its own anti-derivative.
It should be (38): u = a/x.
From equation (33), a² = p/2m². (The square root is negative.) And x² = p/2m. The value of the independent variable, x, has changed. But its differential, #x², remains the same. And the independent variable's differential is the business end of a derivative.
Therefore (39): u = -(1/m)(p/2)^1/2/(p/2m)^1/2
= -1/(m^1/2).
This compares with a supposed second order anti-derivative as equation (28): y = -1/(m-np).
The traditional derivative is equation (40):
du/dx = -(-(1/m)(p/2)^1/2/(p/2m)
= (2/p)^1/2.
In traditional anti-differentiation, the second order anti-derivative is the first order derivative. That is not the logic of a calculus of geometric functions.
Geometric mean differentiation shares some of the main characteristics of traditional differentiation. It works from first principles in a similar way, tho explicitly bounded about the variables, so that there is the extra option of geometric mean differentiation. This is still accomplished by taking the independent variable's differential to a limit of zero, but also in the context of raising its inverse to a power, on both sides of the equation, to effect an exponential version of the geometric mean function, which may be called a geometric mean derivative, because its creation is akin to traditional differentiation.
As with traditional differentiation, it is also possible to infer by rule
an anti-derivative of the geometric mean derivative, usually with the
dependent variable equal to a ratio of constant to independent variable.
Orders of geometric mean derivative and anti-derivative also seem feasible, in their own way. One may speak of orders of geometric mean derivative but a higher order's GM anti-derivative is not generally the lower order of GM derivative, unlike traditional derivatives and anti-derivatives.
An arbitrary constant has to be assumed as an add-on in traditional anti-differentiation. An arbitrary constant has to be assumed as a multiple in GM differentiation, to make determinate, the derivative and its anti-derivative.
The form, ( 1 - z²/2n)^n, is ready for applying the binomial theorem, which expands the factor into a binomial series:
( 1 - z²/2n)^n = 1 - n.z²/2n + {n(n-1)/2!}(z²/2n)^2 - {n(n-1)(n-2)/3!}(z²/2n)^3 + ... =
1 - z²/2 + (n-1){(z²/2)^2}/2!n - (n-1)(n-2){(z²/2)^3}/3!n^2 + ... =
The binomial series is converted to an exponential series by taking variable, n, towards infinity. This effectively cancels the remaining n-terms in the numerator and denominator of each term in the series.
Hence, as n -> ∞
( 1 - z²/2n)^n = 1 - z²/2 + {(z²/2)^2}/2! - {(z²/2)^3}/3! + ...
This is the exponential series for the exponent with the power term, -z²/2. That is: exp^(-z²/2).
Richard Lung.
12 march 2008.
Qualifying paragraph added 26 march 2008.
References:
David Berlinski: A Tour Of The Calculus. The Philosophy of Mathematics. 1995.
P Abbott: Teach Yourself Calculus. 1965. Uses the example of simple and compound interest.